About 6 months ago, I experimented with running a few different multi-modal (vision) language models on my Macbook. At the time, the results weren’t so great.
An experiment#
With a slight modification to the script from that post, I tested out llama3.2-vision 11B (~8GB in size between the model and the projector).
Using uv and inline script dependencies, the full script looks like this
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "ollama",
# ]
# ///
import os
import sys
import ollama
PROMPT = "Describe the provided image in a few sentences"
def run_inference(model: str, image_path: str):
stream = ollama.chat(
model=model,
messages=[{"role": "user", "content": PROMPT, "images": [image_path]}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
def main():
if len(sys.argv) != 3:
print("Usage: python run.py <model_name> <image_path>")
sys.exit(1)
model_name = sys.argv[1]
image_path = sys.argv[2]
if not os.path.exists(image_path):
print(f"Error: Image file '{image_path}' does not exist.")
sys.exit(1)
run_inference(model_name, image_path)
if __name__ == "__main__":
main()
We run it with
uv run vlm.py llama3.2-vision propose_moves.png
As a reminder, this is the propose_moves.png image
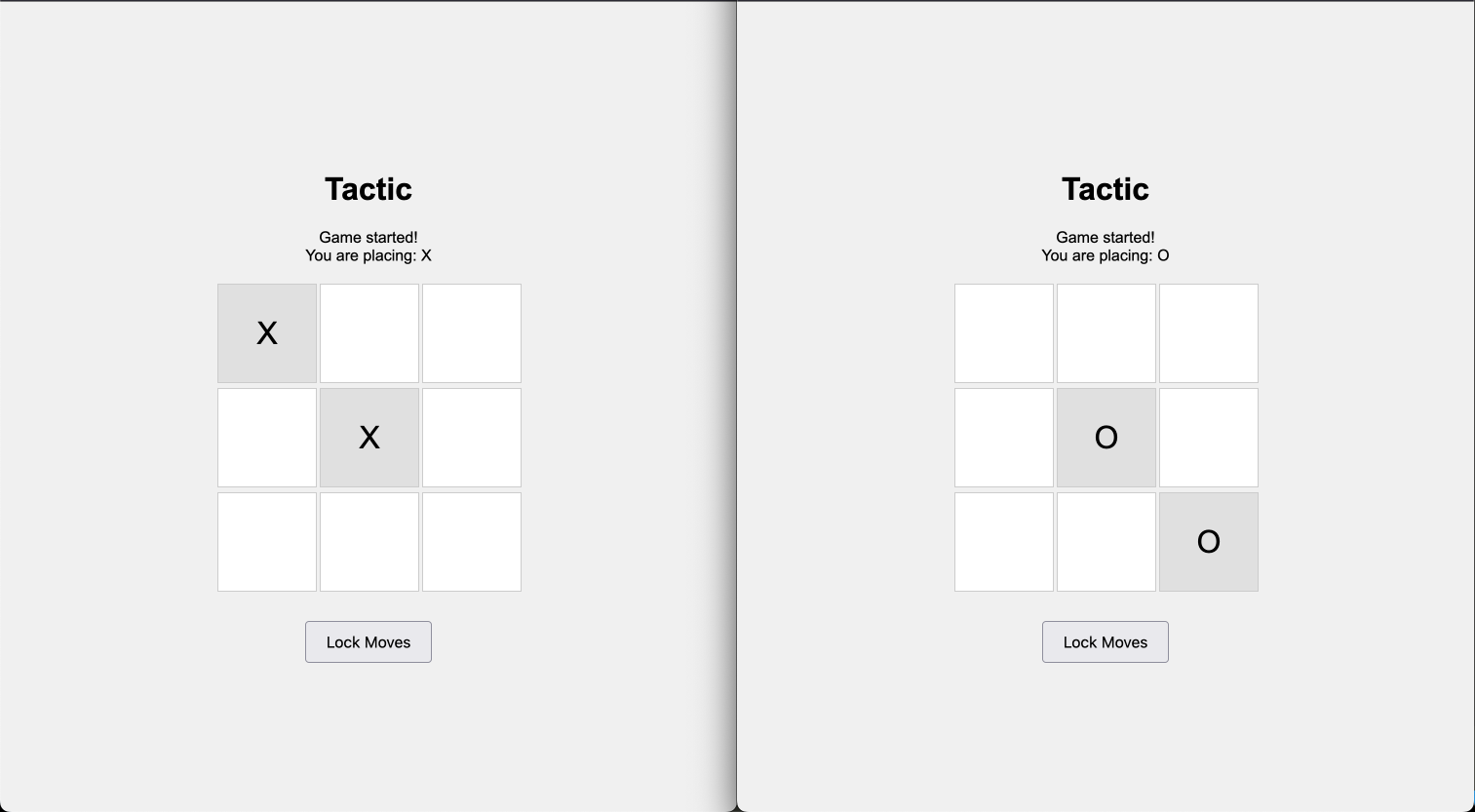
Reading inline script metadata from `vlm.py`
The image shows two game screens side by side, each representing a different position of a game. The left screen is labeled "Tactic" at the top and has an empty gray box under it with the word "Game started!" followed by "You are placing: X". Under that, there's another label that reads "Lock Moves," but no boxes are present below this label. In the middle of the screen, there is a 3x3 grid filled with white squares and two of them have an 'X' in them. The right screen is also labeled "Tactic" at the top, with the same information as the left screen: "Game started!" followed by "You are placing: O". Under that label, there's another "Lock Moves" label without boxes below it. In the middle of this screen, there is a 3x3 grid filled with white squares and two of them have an 'O' in them.
Both screens appear to be part of a game where players take turns placing their marks on a grid. The game seems to involve strategy and planning ahead since each player has limited moves available before the other can respond.%
I was surprised at how good a description this was for such a small model. I played around a bit with structured extraction but the results weren’t particularly good.
Here’s an incorrect example
ollama run llama3.2-vision
>>> Output the board state of board on the left as JSON. Output JSON only. /Users/danielcorin/Desktop/propose_moves.png
Added image '/Users/danielcorin/Desktop/propose_moves.png'
{"board": ["X", "O", "", "", "", "", "", "", ""], "player_turn": "X"}