I’ve done some experimentation extracting structured data from documents using VLMs.
A summary of one approach I’ve tried can be found in my repo, impulse.
I’ve found using Protobufs to be a relatively effective approach for extracting values from documents.
The high-level idea is you write a Protobuf as your target data model then use that Protobuf itself as most of the prompt
I really need a name for this as I reference the concept so frequently.
.
I discussed the approach in more detail in this post so I am going to jump right into it.
The problem#
When relevant contextual data is available in an image, it can be hard to prevent a VLM from hallucinating values that plausibly could be in the image, even when they’re not.
For reference, the image below is a png version of receipt-no-tax-or-totals.pdf which I will reference later.
The data is fake, generated by a model to look realistic.
The example:
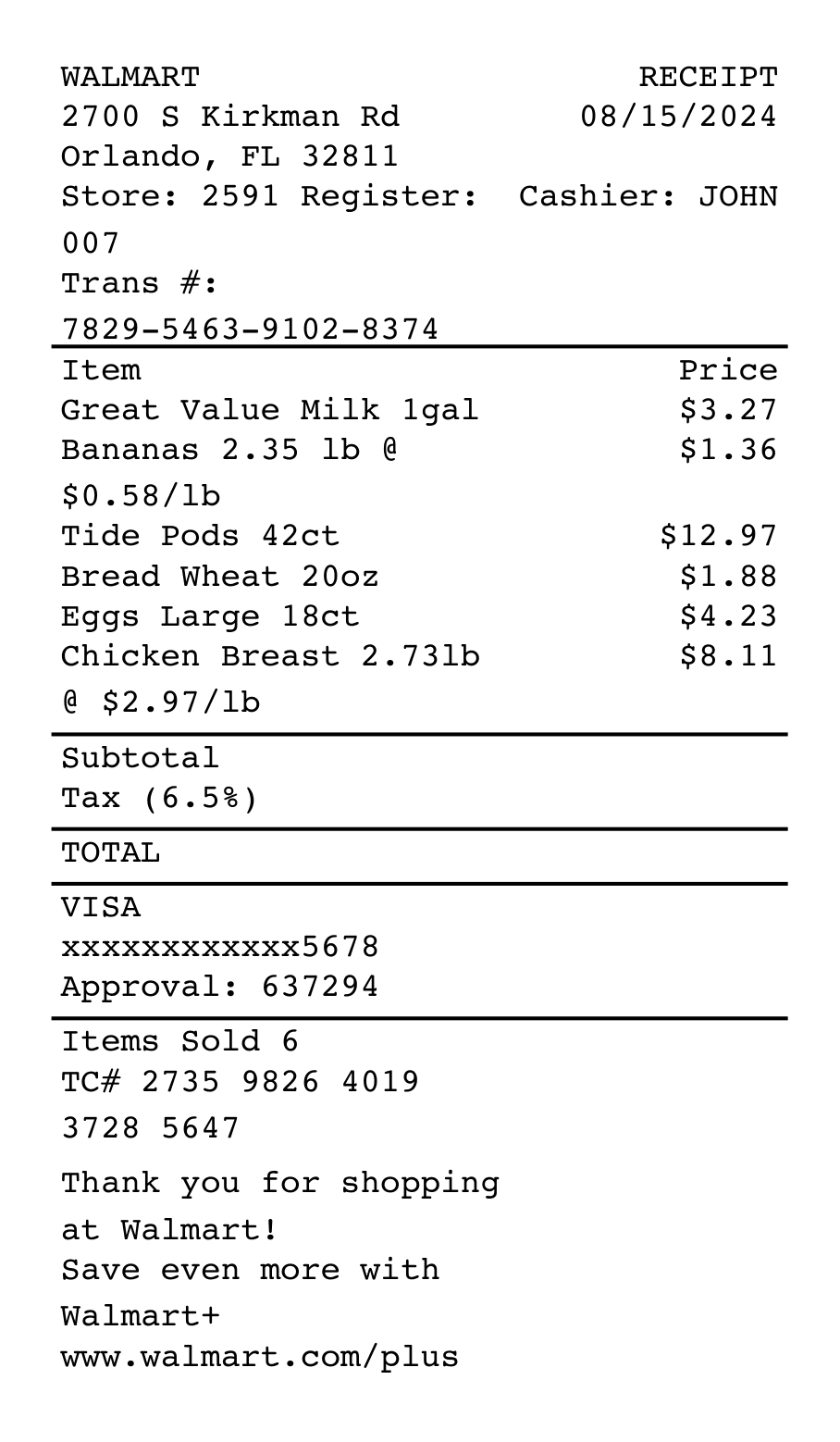
Looking at the model output, we see subtotal, tax and total in the response.
claude-3.5-sonnet has the same challenges.
Why?
In the Protobuf, we specified these fields as optional, yet the model has output them anyway
In some of my testing, I’ve seen the model even output correct values for subtotal, tax and total, but I am definitely not ready to trust them to do math using inference alone.
.
This doesn’t happen every time but it happens far more often than I would like.
We could handwave these results away and say more prompt engineering would help but it doesn’t seem like it does, at least not reliably.
It’s been difficult to find stability to this particular extraction. There are a lot of elements that can be varied.
- the schema (Protobuf, Pydantic, JSON schema, etc.)
- the surrounding prompt, e.g. “… No talk. JSON only”.
- the image quality
- whether the image has the subtotal, tax and total labels (with the values always missing)
I tried 4 different Protobufs against 5 different receipt PDFs.
receipt-original.pdf was a standard receipt with all the data you would expect.
Both models consistently extract the data correctly from these – 8/8 tests were successful.
| Model | Proto | Result | |
|---|---|---|---|
| gpt-4o-2024-08-06 | receipt.proto | receipt-original.pdf | ✅ |
| gpt-4o-2024-08-06 | receipt_comments.proto | receipt-original.pdf | ✅ |
| gpt-4o-2024-08-06 | receipt_item_comments.proto | receipt-original.pdf | ✅ |
| gpt-4o-2024-08-06 | receipt_optionals.proto | receipt-original.pdf | ✅ |
| claude-3-5-sonnet-20240620 | receipt.proto | receipt-original.pdf | ✅ |
| claude-3-5-sonnet-20240620 | receipt_comments.proto | receipt-original.pdf | ✅ |
| claude-3-5-sonnet-20240620 | receipt_item_comments.proto | receipt-original.pdf | ✅ |
| claude-3-5-sonnet-20240620 | receipt_optionals.proto | receipt-original.pdf | ✅ |
As soon as I removed the values for subtotal, tax and total, we start seeing the hallucinations. I tried examples with just the values removed and with the values and labels removed. We see test failures (hallucinations) by both models across all of these examples.
For receipt-no-tax-or-totals.pdf, the receipt with the subtotal, tax and total labels but values missing, 5/8 of the tests fail, meaning the models outputted at least one of these values even though they aren’t actually in the document.
I ran three more rounds of testing for this document specifically.
| Model | Proto | Failures | |
|---|---|---|---|
| gpt-4o-2024-08-06 | receipt.proto | receipt-no-tax-or-totals.pdf | 3/3 |
| gpt-4o-2024-08-06 | receipt_comments.proto | receipt-no-tax-or-totals.pdf | 1/3 |
| gpt-4o-2024-08-06 | receipt_item_comments.proto | receipt-no-tax-or-totals.pdf | 1/3 |
| gpt-4o-2024-08-06 | receipt_optionals.proto | receipt-no-tax-or-totals.pdf | 1/3 |
| claude-3-5-sonnet-20240620 | receipt.proto | receipt-no-tax-or-totals.pdf | 3/3 |
| claude-3-5-sonnet-20240620 | receipt_comments.proto | receipt-no-tax-or-totals.pdf | 2/3 |
| claude-3-5-sonnet-20240620 | receipt_item_comments.proto | receipt-no-tax-or-totals.pdf | 0/3 |
| claude-3-5-sonnet-20240620 | receipt_optionals.proto | receipt-no-tax-or-totals.pdf | 2/3 |
In all but one test, we see hallucinations at least 1/3 times and the only approach for which we don’t (claude-3-5-sonnet-20240620/receipt_item_comments.proto) is pretty kludgy.
syntax = "proto3";
package receipt_item_comments;
message Receipt {
string merchant = 1;
string date = 2;
repeated LineItem line_items = 3;
// do not extract unless value is present
float subtotal = 4;
// do not extract unless value is present
float tax = 5;
// do not extract unless value is present
float total = 6;
}
message LineItem {
string item = 1;
float price = 2;
}
Takeaways#
There are lots more things to try here, and I don’t believe these results preclude the use of VLMs for data extraction from documents, but it’s important not to blindly trust the models. They will make things up, often in a way that seems to make sense, but may not be correct.
Afterword#
After running these experiments, I read a post from Anton about the quality of Gemini as a VLM.
been doing a lot more work with images using VLMs and basically finding that none of the open source vision models come close to the capabilities of gemini flash. this includes extracting text using OCR, captioning, generating keywords and classification. even though some of the…
— anton (@abacaj) August 16, 2024
Following Google’s docs, I ran the same experiments above for Gemini (gemini-1.5-flash-latest).
I will reiterate my appreciation for the simplicity of the process of getting an API key to use Gemini.
I probably wouldn’t have tried if I needed to wade through GCP to do it.
gemini-1.5-flash-latest seems to be better about not hallucinating values!
However, it struggles to extract all the correct data from the more unusual receipt I generated.
These results are a different flavor than OpenAI and Anthropic’s.
I don’t have a strong appreciation for the differences in model architecture, but part of me wonders if that is contributing to the differences in results.
Let me know if I am totally off about that.
A brief search brought me to this paper which seems to indicate gemini-1.5-flash-latest uses a mixture of experts architecture whereas I believe gpt-4o-* uses a transformer architecture.
These results were good and interesting enough that I figured I would also run them against gemini-1.5-pro-latest to see what would happen.
Pretty much all the tests failed.
I imagine this is a bit of a claude-3.5-sonnet vs claude-3-opus situation (the former being a newer release and generally better in my experience).
This experiment was my first dive into using a Google model which was a straightforward and enjoyable experience.
Code#
If you want to run the tests I ran, you can find the code here.