In light of OpenAI releasing structured output in the model API, let’s move output structuring another level up the stack to the microservice/RPC level.
A light intro to Protobufs#
Many services (mostly in microservice land) use Protocol Buffers (protobufs) to establish contracts for what data an RPC requires and what it will return. If you’re completely unfamiliar with protobufs, you can read up on them here.
Here is an example of a message that a protobuf service might return.
syntax = "proto3";
message Receipt {
string id = 1;
string merchant = 2;
float total_amount = 3;
string date = 4;
}
Here’s a very simple service that makes use of that message.
service ReceiptService {
rpc GetReceipt (ReceiptRequest) returns (Receipt);
}
message ReceiptRequest {
string id = 1;
}
Protobuf messages define the container into which data is packed and sent back to the caller.
Protobuf messages and services typically live in .proto files.
A tool called protoc can be used to generate code in the language of your choice to help you interact with a system that requires and responds with protobufs.
Extraction with a model#
Similar to how we can use libraries like Pydantic (via libraries like instructor) and targeted prompting to get Pydantic objects in and out of a model, we can accomplish something quite similar with protobufs.
The benefit of using protobufs rather than Pydantic, is they are a language agnostic data interchange format.
It doesn’t matter what language our caller or our server uses – the following approach can still be applied.
A simple example#
We’ve seen this before. Let’s try more things.
Data extraction with VLMs#
We now have Vision Models can do inference and perform tasks with images in the context.
Let’s prompt the model to extract data from a screenshot I took while finetuning gpt-3.5.turbo.
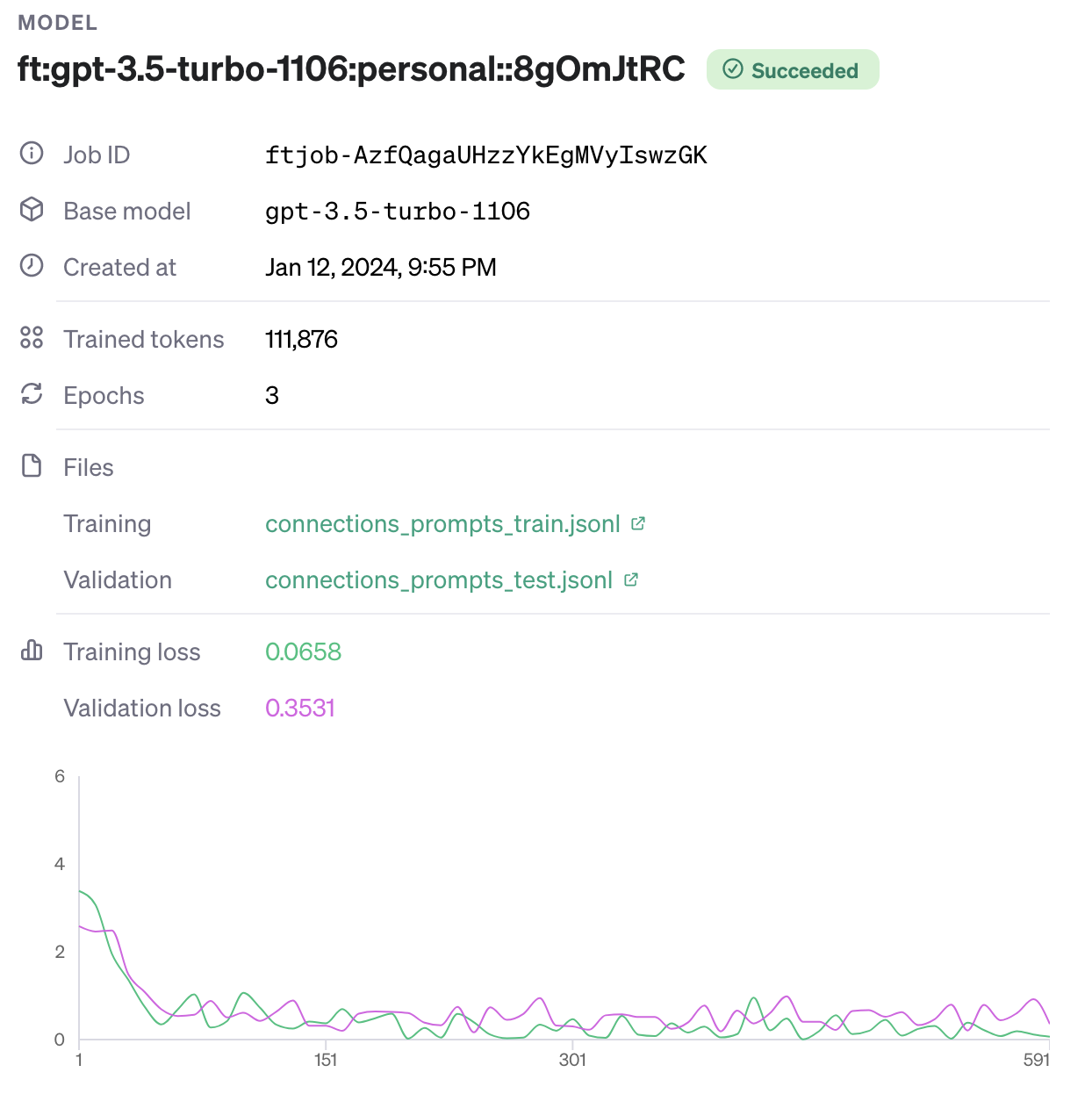
This seems to work quite well.
Parameterize the approach#
A parameterized version of the prompts above looks like this.
This next part is a bit unusual but stick with me.
We can setup a gRPC server and proto service that accepts a path to a .proto and a file path and responds with the Protobuf and JSON versions of the extraction using the approach above with a model. E.g.
syntax = "proto3";
package extract;
import "google/protobuf/any.proto";
service ExtractService {
rpc ExtractData (ExtractRequest) returns (ExtractResponse) {}
}
message ExtractRequest {
string proto_schema = 1;
string file_path = 2;
}
message ExtractResponse {
google.protobuf.Any proto_instance = 1;
string json_result = 2;
}
If we assume we have the working server described above, given the FinetuneJob object above, here is what an example request script might look like
import grpc
from extract_pb2 import ExtractRequest
from extract_pb2_grpc import ExtractServiceStub
# Setup gRPC channel and client
channel = grpc.insecure_channel('localhost:50051')
client = ExtractServiceStub(channel)
# ":FinetuneJob" indicates to the server that a instance of the `FinetuneJob` object should be extracted
# There are several other ways you could design this
# This way was fast to implement
proto_schema = "/path/to/finetunejob.proto:FinetuneJob"
file_path = "/path/to/finetune_job_image.jpg"
# Create the request
request = ExtractRequest(proto_schema=proto_schema, file_path=file_path)
# Make the RPC call
response = client.ExtractData(request)
# Print the results
print("JSON Result:", response.json_result)
print("Proto Instance:", response.proto_instance)
For this example, our server is running on the same system as the client. The server
- receives the request above
- reads the image and
.protofiles from the file system - builds a prompt
- makes a call to a model to do inference to extract the desired data in adherence to the specified protobuf message schema
- returns the protobuf message as a
google.protobuf.Anytype, which can be unpacked by the client into the specific message type passed in
With this approach, we now have a Protobuf service that returns a Protobuf message in the schema we describe. However, more interestingly, we can modify the extraction instructions and resulting structure of the returned protobuf message by modifying the message itself.
In the FinetuneJob example above, it we also want to extract status from the image, we only need to augment the message:
syntax = "proto3";
message FinetuneJob {
string model_name = 1;
string job_id = 2;
string base_model = 3;
string created_at = 4;
int32 trained_tokens = 5;
int32 epochs = 6;
repeated File files = 7;
float training_loss = 8;
float validation_loss = 9;
string status = 10;
}
message File {
string type = 1;
string name = 2;
}
Running the inference again with the same prompt above and updated protobufs, yields
{
"model_name": "ft:gpt-3.5-turbo-1106:personal::8gOmJtRC",
"job_id": "ftjob-AzfQagaUHzzYkEgMVyIswzGK",
"base_model": "gpt-3.5-turbo-1106",
"created_at": "Jan 12, 2024, 9:55 PM",
"trained_tokens": 111876,
"epochs": 3,
"files": [
{
"type": "Training",
"name": "connections_prompts_train.jsonl"
},
{
"type": "Validation",
"name": "connections_prompts_test.jsonl"
}
],
"training_loss": 0.0658,
"validation_loss": 0.3531,
"status": "Succeeded"
}
Note the last item status now has the expected value "Succeeded".
Try it out#
I wrote up a more complete proof-of-concept in this repo.