OpenAI popularized a pattern of streaming results from a backend API in realtime with ChatGPT. This approach is useful because the time a language model takes to run inference is often longer than what you want for an API call to feel snappy and fast. By streaming the results as they’re produced, the user can start reading them and the product experience doesn’t feel slow as a result.
OpenAI has a nice example of how to use their client to stream results. This approach makes it straightforward to print each token out as it is returned by the model. Most user facing apps aren’t command line interfaces, so to build our own ChatGPT like experience where the tokens show up in realtime on a user interface, we need to do a bit more work. Using Server-Sent Events (SSE), we can display results to a user on a webpage in realtime.
If you’re short on time, Vercel wrote a nice ai library that handles much of the work we’re about to do here in React, with nice hooks and an easy pattern for hosting a backend (through proprietary).
This exploration is to understand SSE more deeply and look at what it takes to build your own API and UI capable of the UX described.
A simple implementation#
We’re going to build a fastapi backend to stream tokens from OpenAI to a frontend, which I will build as well.
Let’s start with a simple server that returns at StreamingResponse.
server.py
from openai import AsyncOpenAI
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
client = AsyncOpenAI()
async def generator(msg: str):
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": msg,
}
],
model="gpt-3.5-turbo",
stream=True,
)
async for chunk in stream:
yield chunk.choices[0].delta.content or ''
@app.get("/")
async def main(msg):
return StreamingResponse(generator(msg))
Run the server
uvicorn server:app --reload
Curl the endpoint shows things are wired together reasonably
❯ curl "localhost:8000/ask?msg=who%20are%20you"
I am an AI chatbot developed by OpenAI. I am here to provide information and assist with any questions you have. How can I help you today?%
This is almost all we need on the server for an MVP of streaming to a UI.
Referencing the same SSE docs as earlier, we see a description of an interface called EventSource.
We’ll see a simple html and Javascript frontend with EventSource to build our UI.
Looking at the example PHP code, we also see our server code needs some slight modifications.
The data we emit needs to be formatted as f"data: {data}\n\n" for EventSource to handle it.
We also need to set the content type of text/event-stream.
Here is the server with those changes:
from openai import AsyncOpenAI
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
client = AsyncOpenAI()
async def generator(msg: str):
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": msg,
}
],
model="gpt-3.5-turbo",
stream=True,
)
async for chunk in stream:
yield f"data: {chunk.choices[0].delta.content or ''}\n\n"
@app.get("/ask")
async def main(msg):
return StreamingResponse(generator(msg), media_type="text/event-stream")
And the curl still works (though now is less human readable).
data:
data: I
data: am
data: an
data: AI
data: language
data: model
data: created
data: by
data: Open
data: AI
data: .
data: I
data: am
data: designed
data: to
data: assist
data: and
data: provide
data: information
data: to
data: the
data: best
data: of
data: my
data: abilities
data: .
data:
Now let’s create a simple UI and serve it from the server (for simplicity).
index.html
<!DOCTYPE html>
<html>
<head>
<title>Stream Test</title>
</head>
<body>
<button id="streambtn">Start Streaming</button>
<input type="text" id="messageInput" placeholder="Enter message">
<div id="container"></div>
<script>
var source;
var button = document.getElementById('streambtn');
var container = document.getElementById('container');
var input = document.getElementById('messageInput');
button.addEventListener('click', function() {
var message = input.value;
var url = 'ask/?msg=' + encodeURIComponent(message);
// clear the input field and container div
input.value = '';
container.textContent = '';
// create new EventSource connected to the server endpoint
source = new EventSource(url);
source.addEventListener('open', function(e) {
console.log('Connection was opened');
}, false);
source.addEventListener('message', function(e) {
// Append the new message to the existing text
container.textContent += e.data;
}, false);
source.addEventListener('error', function(e) {
if (e.readyState == EventSource.CLOSED) {
console.log('Connection was closed');
}
else {
console.log('An error has occurred');
}
}, false);
});
</script>
</body>
</html>
We also modify the server to render with html file when request the root url.
from openai import AsyncOpenAI
from fastapi import FastAPI
from fastapi.responses import FileResponse, StreamingResponse
app = FastAPI()
client = AsyncOpenAI()
async def generator(msg: str):
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": msg,
}
],
model="gpt-3.5-turbo",
stream=True,
)
async for chunk in stream:
yield f"data: {chunk.choices[0].delta.content or ''}\n\n"
@app.get("/ask")
async def main(msg):
return StreamingResponse(generator(msg), media_type="text/event-stream")
@app.get("/")
async def get_index():
return FileResponse("index.html")
We can open the site at http://localhost:8000 and enter a message to the model. Then click “Start Streaming”.
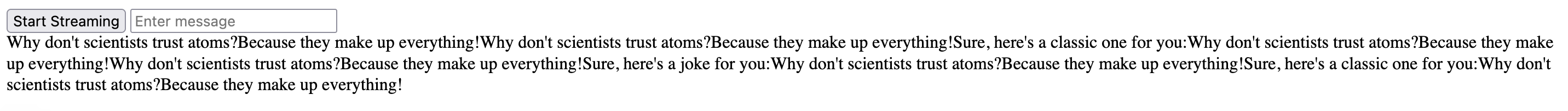
We see the response from the model showing up in real-time! Something funny happens though. If we wait a few seconds, we see new responses to the message continue coming through, as if the request is being submitted repeated it. In fact, this is exactly what is happening.
We can modify the server to see a [DONE] response when the streaming is complete and the client to close the EventSource connection when it receives this data.
from openai import AsyncOpenAI
from fastapi import FastAPI
from fastapi.responses import FileResponse, StreamingResponse
app = FastAPI()
client = AsyncOpenAI()
async def generator(msg: str):
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": msg,
}
],
model="gpt-3.5-turbo",
stream=True,
)
async for chunk in stream:
yield f"data: {chunk.choices[0].delta.content or ''}\n\n"
yield f"data: [DONE]\n\n"
@app.get("/ask")
async def main(msg):
return StreamingResponse(generator(msg), media_type="text/event-stream")
@app.get("/")
async def get_index():
return FileResponse("index.html")
<!DOCTYPE html>
<html>
<head>
<title>Stream Test</title>
</head>
<body>
<button id="streambtn">Start Streaming</button>
<input type="text" id="messageInput" placeholder="Enter message">
<div id="container"></div>
<script>
var source;
var button = document.getElementById('streambtn');
var container = document.getElementById('container');
var input = document.getElementById('messageInput');
button.addEventListener('click', function() {
// create new EventSource connected to the server endpoint
var message = input.value;
var url = 'ask/?msg=' + encodeURIComponent(message);
// clear the input field and container div
input.value = '';
container.textContent = '';
source = new EventSource(url);
source.addEventListener('open', function(e) {
console.log('Connection was opened');
}, false);
source.addEventListener('message', function(e) {
// if the message is "[DONE]", close the connection
if (e.data === '[DONE]') {
source.close();
console.log('Connection was closed');
return;
}
// append the new message to the existing text
container.textContent += e.data;
}, false);
source.addEventListener('error', function(e) {
if (e.readyState == EventSource.CLOSED) {
console.log('Connection was closed');
}
else {
console.log('An error has occurred');
}
}, false);
});
</script>
</body>
</html>
Now when we submit a message from the UI, the client closes the connection with the server after it is finished responding.
If we submit another request, the client clears the content and streaming the new response.
It generally works.
The weirdness in the spacing is due to the model returning newlines (\n) which are being consumed by EventSource as the suffix of data.
That is a problem we won’t delve into here.
Repurposing the backend#
EventSource works for streaming events from a backend with SSE, but there are other options depending on how you’re building your UI.
As mentioned earlier, Vercel’s ai package provides React hooks to build a realtime streaming chat.
We can modify our backend to support this library.
Let’s first consider a minimal (as much as possible anyway) Next.js app with the ai library installed, taken straight from the docs
src/app/page.tsx
"use client";
import { useChat } from "ai/react";
export default function Home() {
const { messages, input, handleInputChange, handleSubmit } = useChat({
api: "http://127.0.0.1:8000/ask"
});
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<div>
{messages.map((m) => (
<div key={m.id}>
{m.role === "user" ? "User: " : "AI: "}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<label>
Say something...
<input value={input} onChange={handleInputChange} />
</label>
<button type="submit">Send</button>
</form>
</div>
</main>
);
}
We’ve setup the useChat hook to point to our backend and wired up an input field to submit the conversation along with a new message.
If we inspect the payload the ai sends to the backend, we see it’s a POST request and that the body content contains the OpenAI schema for an array of messages.
{
"messages": [
{"role": "user", "content": "..."}
]
}
With this knowledge, we can modify our backend to expect this request schema and pass it to the model.
Through some quick trial and error (maybe the docs have this somewhere as well), I also learned the library expects the streaming responses to contain the tokens only, not the data: {content}\n\n\ wrapping like EventSource does.
Our server code now looks like this
from openai import AsyncOpenAI
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import StreamingResponse
app = FastAPI()
# Added because the frontend and this backend run on separate ports
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
client = AsyncOpenAI()
@app.post("/ask")
async def ask(req: dict):
stream = await client.chat.completions.create(
messages=req["messages"],
model="gpt-3.5-turbo",
stream=True,
)
async def generator():
async for chunk in stream:
yield chunk.choices[0].delta.content or ""
response_messages = generator()
return StreamingResponse(response_messages, media_type="text/event-stream")
Here’s how it looks (sorry, no fancy UI):
