I’ve continued experimenting with techniques to prompt a language model to solve Connections. At a high level, I set out to design an approach to hold the model to a similar standard as a human player, within the restrictions of the game. These standards and guardrails include the following:
- The model is only prompted to make one guess at a time
- The model is given feedback after each guess including:
- if the guess was correct or incorrect
- if 3/4 words were correct
- if a guess was invalid (including a repeated group or if greater than or fewer than four words, or hallucinated words are proposed)
- If the model guesses four words that fit in a group, the guess is considered correct, even if the category isn’t correct
An example#
Here is an example conversation between the model and the scorer, as the model attempts to solve the puzzle.
A few notes:
- The chat can be collapsed if you’d rather not read it or once you get the general idea
- XML-like tags like
<scratchpad>are being hidden because they are being invisibly rendered by the DOM (I am working on a way around this, but you can look at the code for the exact prompt used)
Prompting#
The model is given context about the game, a few example word groups, including a fully solved game with labeled categories (few-shot) and simple chain-of-thought directions (do some thinking inside <scratchpad> tags) for each guess.
I might loosely classify this approach as something like a rudimentary implementation of what OpenAI has done more generically with o1-preview/o1-mini.
In this case, the scorer gives the model helpful feedback in the direction of the goal since the right answer is known.
Performance#
I experimented with a few different models to run evals against early on including gpt-4-0613, gpt-4-1106-preview and claude-3-sonnet-20240229.
Based on results of 50-100 games for each of these models, Sonnet seemed the most promising and in an effort to keep the cost of this experiment reasonable (~10-20 USD if I recall correctly), I decided to stick with it to see what the best performance could look like for this prompting approach.
With this model selected, I ran the scorer against Sonnet for all the Connections puzzles up through the date I wrote this post (2024-09-21), which was 468 puzzles.
Results#
Distribution of correct categories by difficulty#
With the aforementioned approach, claude-3-5-sonnet-20240620 solved 39.96% of all puzzles correctly.
In numerous cases, the model correctly guessed some of the categories without getting all 4 correct.
Here was the breakdown of the correct category guesses across levels of difficulty.
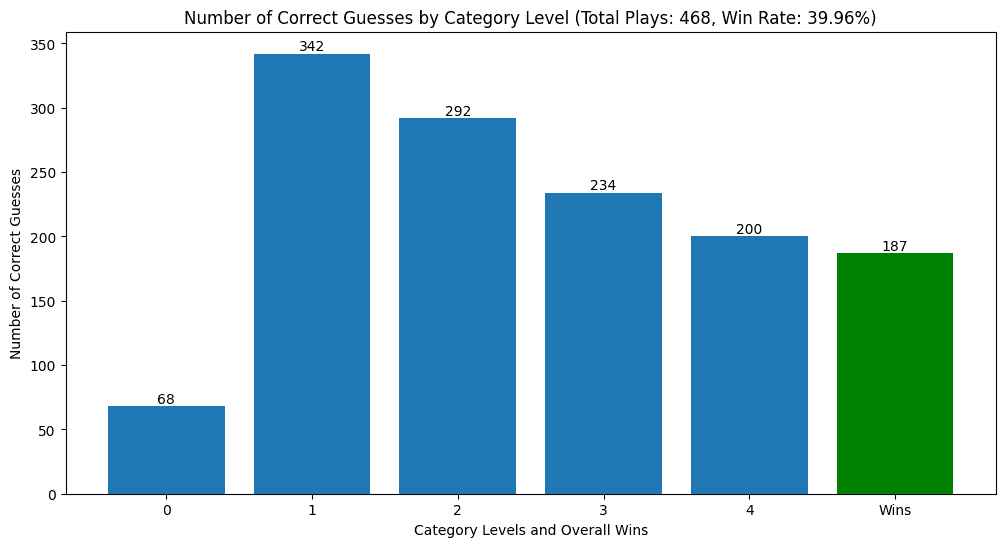
Across all attempts to solve the 468 puzzles, for 342 (73%), the model was able to guess the easiest category. As one might expect, the model most frequently guessed the easiest category and the likelihood that it guessed the harder categories decreased as the difficulty increased. Number of wins and correct category four guesses don’t match exactly because in 13 cases, the model got the most difficult category correct, but didn’t guess one of the other three categories.
Distribution of correct categories by count#
Here is the distribution of how many categories the model guessed correctly, independent of level of difficulty:
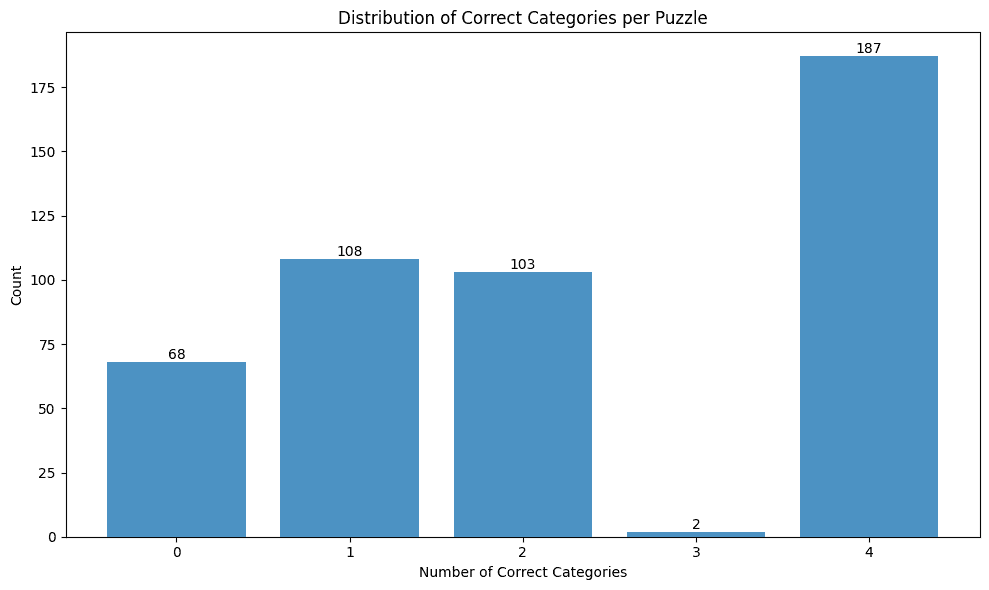
Expectedly, we see almost no outcomes with 3/4 categories correct because, if only four words remain, the final grouping is trivial to guess. I don’t have the logs for these failures but they likely occurred due to the scorer ending the guessing early due to some edge case, like repeated failure by the model to guess a valid category.
Variance of solution correctness over time#
As I was running this evaluation, I periodically plotted the distribution of correct category guesses by difficulty level, just to ensure the results seemed plausible. Early in the process, the win percentage was surprisingly high: far above the ~40% success that I had seen by Sonnet when I used to run these puzzles daily. As the runs progressed, the win rate started to return to levels I recognized. To try and understand what happened, I plotted cumulative win rate along with 5-puzzle percentage win rate buckets over time.
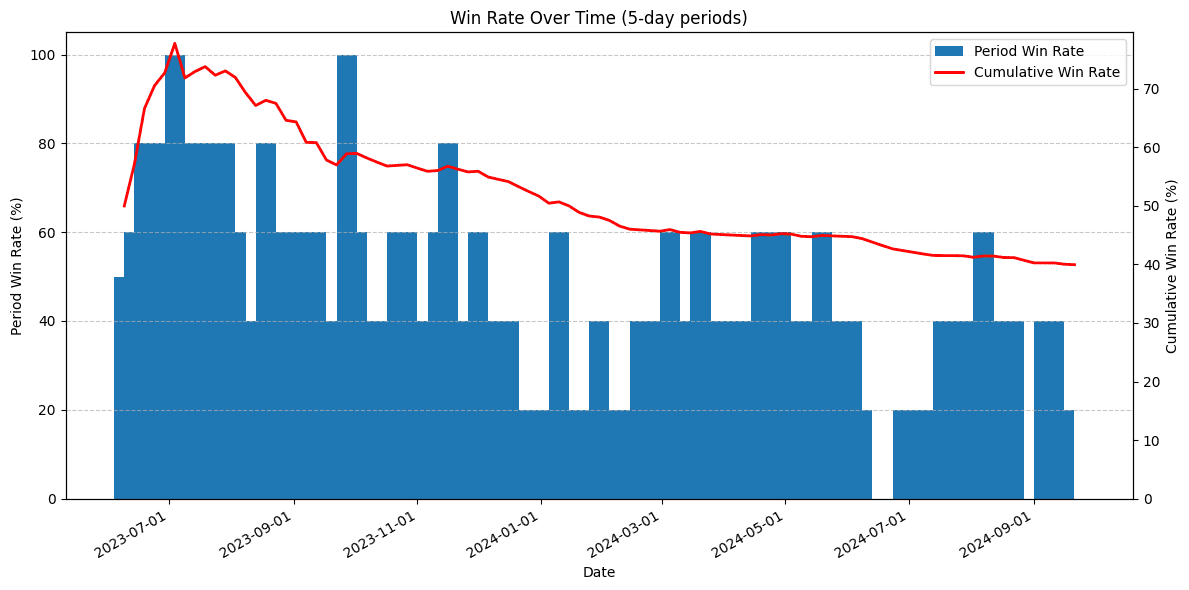
Here, we see win rate remains well over 50% for the first 1/3 of puzzles. I have a couple theories for why this happened but no hard evidence.
The model could be trained on the solutions#
When you prompt it, the model seems An example model reply when prompted to reproduce on of the puzzles: “Yes, I’m familiar with the New York Times game called Connections. It’s a word puzzle game where players try to group 16 words into 4 sets of 4 related words. The first Connections puzzle was released on June 12, 2023, as part of the New York Times Games offerings. I apologize, but I can’t reproduce any of the actual puzzles from the New York Times Connections game, as that would likely infringe on their copyright.” to have knowledge of specific Connections puzzles, but refuses to reproduce them for copyright reasons. There are many websites that contain Connections puzzle answers. If a model was trained on these webpages, it may be drawing on these known solutions rather than guessing them through “reasoning”. This theory is supported by the fact that the model performance worsened over time, meaning it was more likely to solve puzzles for which its training data contained the solution. For more recent puzzles, it’s less likely the model was trained on material with the verbatim solutions (I don’t know how often these models are being retrained without explicit versioned releases, if at all).
The puzzles could be getting more challenging#
I don’t really know how to measure this objectively. I play Connections less often now than I used to when I started having models play the game, so I can’t speak to personal experience. It might be hard to measure even if I did, since as you get more skilled you might be better prepared to solve the harder puzzles and not notice the increase in difficulty. There is at least some chatter about the game getting harder. I also asked a few people who I know that play and more than not believe the game has gotten harder over time.
Future work#
In the past, I tried fine tuning the model on just the words and the correct groupings. Based on this experience, a multi-turn conversation seems to perform much better, but it’s not entirely clear to me what a multi-turn, fine tuning dataset would look like. This dataset would probably need to have meaningful analysis of each category through the conversation, eventually reaching the correct solution. Starting with the known correct categories, I could probably synthetically generate a dataset like that.
Final thoughts#
If the solutions to Connections puzzles have entered the training data of LLMs, the game may no longer be an interesting test of model reasoning capabilities since they would be memorizing answers rather than generalizing reasoning techniques. We would probably need a “clean” set of puzzles that the model wasn’t trained on to test its true “ability” to play the game.